ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models (ICLR 2024)
Can video-language models process spatio-temporal events sufficiently?
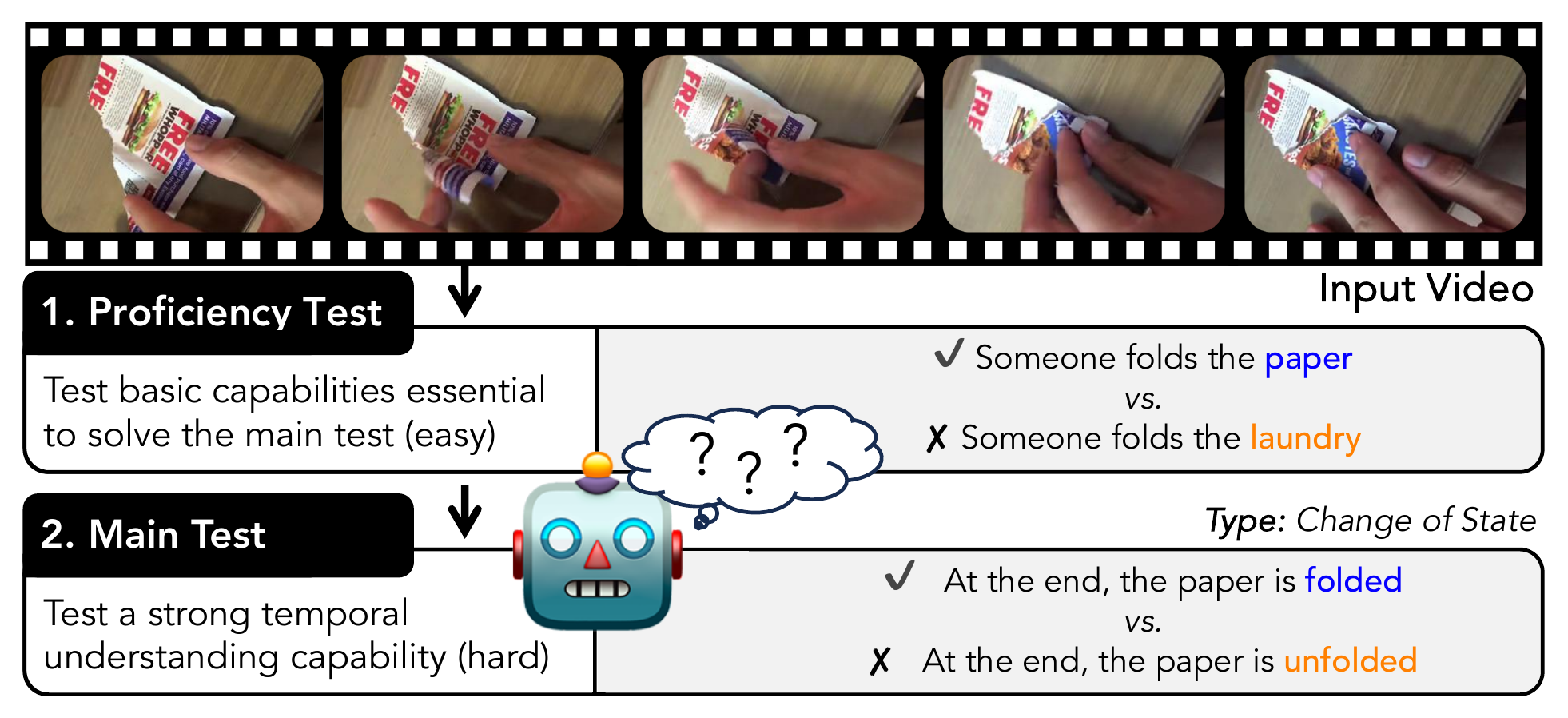
ViLMA (Video Language Model Assessment) presents a comprehensive benchmark for Video-Language Models (VidLMs) to evaluate their linguistic and temporal grounding capabilities in five dimensions: action counting, situation awareness, change of state, rare actions and spatial relations.
ViLMA also includes a two stage evaluation procedure as (i) proficiency test (P) that assesses fundamental capabilities deemed essential before solving the five tests, (ii) main test (T) which evaluates the model under the proposed five diverse tests, and (iii) a combined score of these two tasks (P+T).
ViLMA (Video Language Model Assessment) presents a comprehensive benchmark for Video-Language Models (VidLMs) to evaluate their linguistic and temporal grounding capabilities in five dimensions: action counting, situation awareness, change of state, rare actions and spatial relations.
ViLMA also includes a two stage evaluation procedure as (i) proficiency test (P) that assesses fundamental capabilities deemed essential before solving the five tests, (ii) main test (T) which evaluates the model under the proposed five diverse tests, and (iii) a combined score of these two tasks (P+T).
Paper
For more details about benchmark and experiments, please read our paperour paper.
@inproceedings{kesen2023vilma,
title={ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models},
author={Ilker Kesen and Andrea Pedrotti and Mustafa Dogan and Michele Cafagna and Emre Can Acikgoz and Letitia Parcalabescu and Iacer Calixto and Anette Frank and Albert Gatt and Aykut Erdem and Erkut Erdem},
year={2024},
booktitle={International Conference on Learning Representations (ICLR)},
}ViLMA Leaderboard
We aim to maintain an up-to-date leaderboard for the ViLMA benchmark. To make a submission, please either send an email to Ilker Kesen or open an issue. For simplicity, the leaderboard represents only the combined setting (P+T) results using the pairwise accuracy metric (accr). , and icons characterise text-only models, image-language models and video-language models respectively.Authors

Ilker Kesen

Andrea Pedrotti

Mustafa Dogan

Michele Cafagna

Emre Can Acikgoz

Letiția Pârcălăbescu
Iacer Calixto

Anette Frank

Albert Gatt

Aykut Erdem
