
|
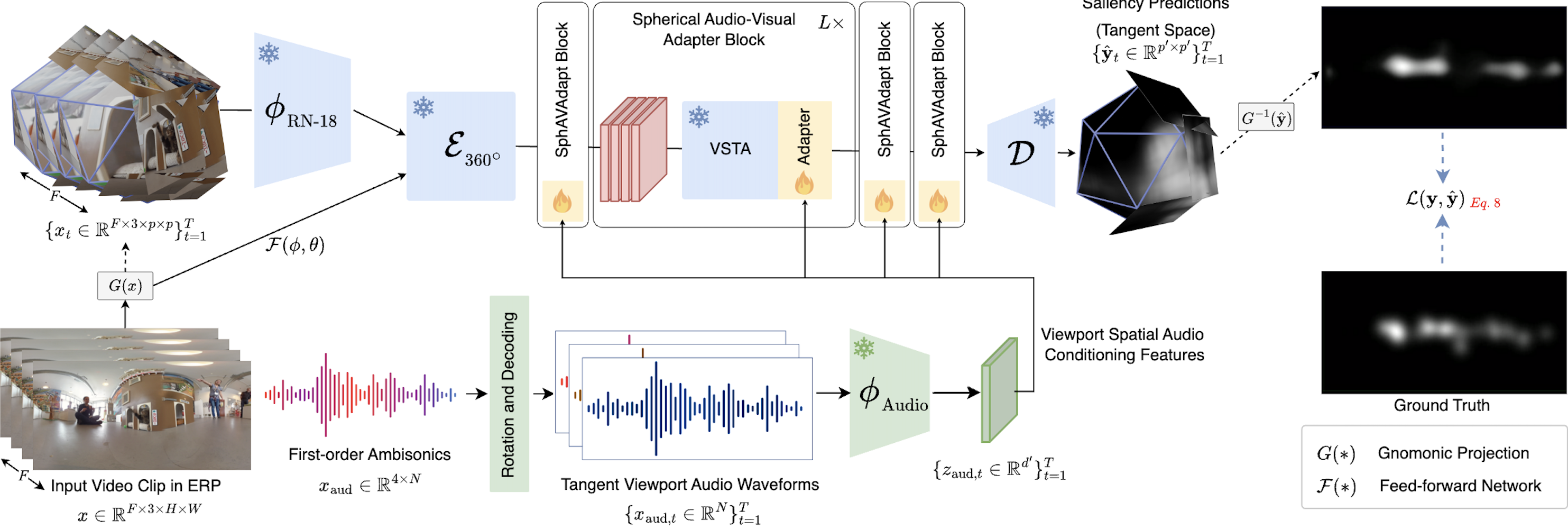
SalViT360 |
SalViT360 Appendix |
Code |
Models |
Supplementary Videos |
YT360-EyeTracking Dataset |
@misc{cokelek2023spherical,
author={Cokelek, Mert and Ozsoy, Halit and Imamoglu, Nevrez and Ozcinar, Cagri and Ayhan, Inci and Erdem, Erkut and Erdem, Aykut},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={Spherical Vision Transformers for Audio-Visual Saliency Prediction in 360$^{\circ }$∘ Videos},
year={2026},
volume={48},
number={1},
pages={329-345},
keywords={Videos;Visualization;Spatial audio;Predictive models;Transformers;Faces;Ambisonics;MONOS devices;Distortion;Convolution;Audio-visual saliency prediction;360 $^\circ$ ∘ videos;vision transformers;adapter fine-tuning},
doi={10.1109/TPAMI.2025.3604091}
}
For any questions, please contact Mert Cokelek at mcokelek21@ku.edu.tr or Halit Ozsoy at halitozsoy1584@gmail.com.